Régression logistique sur variable dichotomique: Introduction
De la variable dichotomique au modèle logistique : comprendre et interpréter la régression logistique.
Présentation de la régression logistique
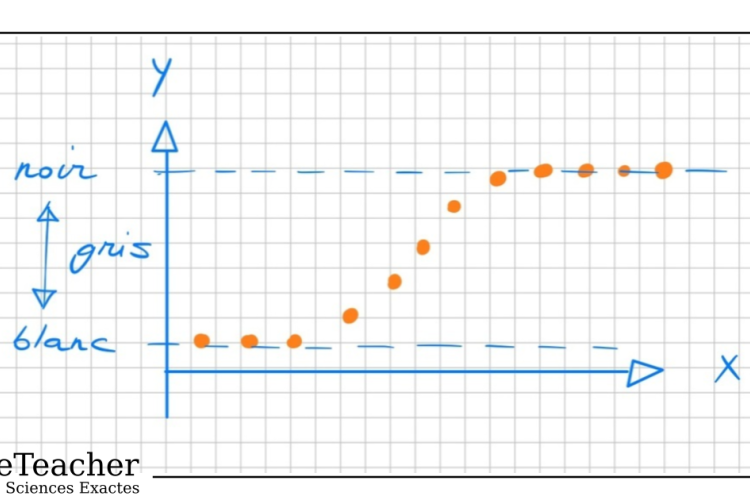
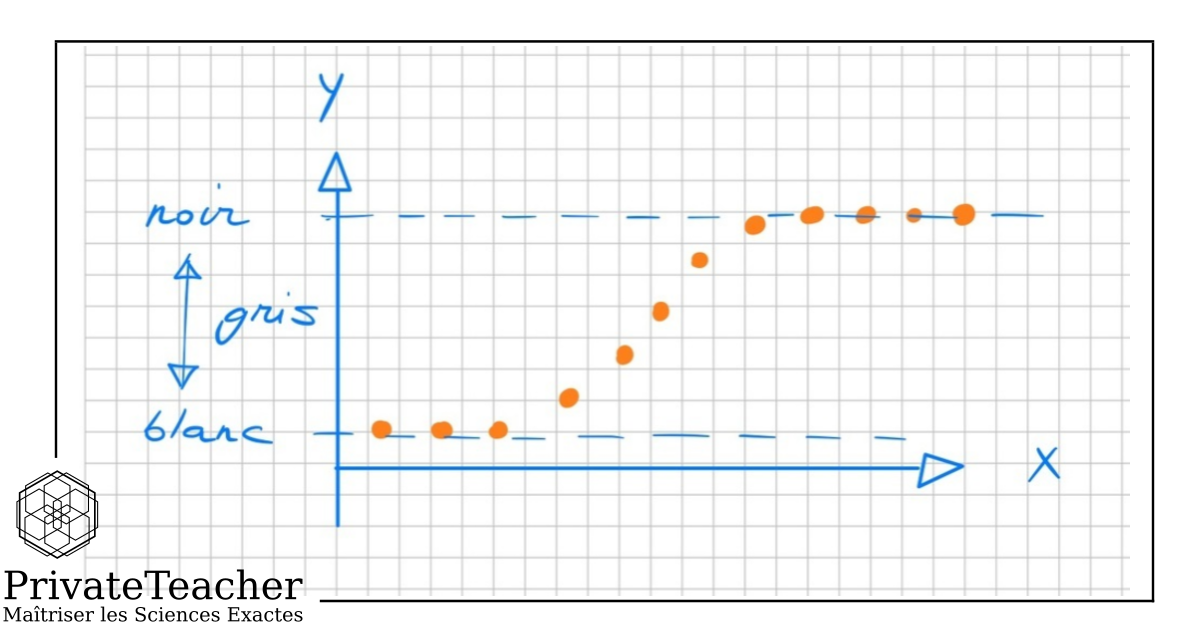
Nous autres êtres humains sommes parfois sujets à des changements d’humeur. Une bonne nouvelle, par exemple, peut nous faire passer d’un état morose à un état enjoué. On peut vouloir comprendre comment les individus passent d’un état à un autre par le biais d’une variable. Si l’on ne s’intéresse qu’à deux états d’humeur, par exemple, la variable qui représente ces états ne possède alors que deux modalités. On parle alors de variables dichotomiques. La régression logistique est un outil mathématique dont on se sert pour étudier le comportement des variables dichotomiques en fonction d’un paramètre x, le nombre de bonnes nouvelles reçu dans la journée, par exemple.
Pourquoi utiliser la régression logistique
On utilise les régressions logistiques pour comprendre la transition entre les deux modalités d’une variable dichotomique. On aboutit alors à un modèle logistique. Ce modèle nous permet de comprendre comment se fait la transition d’un état à un autre et donc de comprendre quels paramètres interviennent dans le changement d’état.
A qui s'adresse ce document
Ce document s’adresse aux étudiants-es à qui l’on demande de savoir lire et interpréter les résultats d’une régression logistique donnée par un logiciel tel que R, STATA ou SPSS. Ce document sera utile à toute personne cherchant à perfectionner leurs connaissances dans la modélisation des données et l’utilisation des modèles avancés tels que les régressions logistiques multinomiales.
Prérequis
Le document suppose une première exposition à la régression linéaire simple. Les concepts suivants doivent être connus : significativité statistique d'un coefficient, résidu d'un modèle, coefficient de détermination R². La régression logistique en est une extension directe : le passage d'une variable continue à une variable dichotomique introduit la transformation logit, mais la logique d'interprétation des coefficients reste comparable. Aucune dérivation mathématique n'est requise — l'objectif est la compréhension conceptuelle et la lecture des sorties logicielles.
Questions courantes FAQ
Qu'est-ce que la régression logistique ?
La régression logistique est un modèle statistique utilisé lorsque la variable dépendante est dichotomique. Elle prédit la probabilité d'appartenir à l'une des deux catégories à partir d'un ou plusieurs prédicteurs. Elle ne modélise pas directement cette probabilité mais son logit — le logarithme des cotes — ce qui garantit des prédictions dans l'intervalle [0, 1] et rend la relation linéarisable.
Qu'est-ce que la fonction logit ?
La fonction logit transforme une probabilité p ∈ [0, 1] en une valeur réelle quelconque. Sa formule est logit(p) = ln(p / (1 − p)). Le rapport p / (1 − p) est la cote — la probabilité d'un événement divisée par celle qu'il ne se produise pas. Le logit est le logarithme naturel de cette cote. Cette transformation rend la relation entre prédicteurs et variable dépendante modélisable sous forme linéaire.
Comment interpréter un coefficient de régression logistique ?
Un coefficient b exprime le changement du logit pour une augmentation d'une unité du prédicteur, toutes choses égales par ailleurs. On exponentie b pour obtenir le rapport de cotes : OR = e^b. L'OR indique combien de fois la cote est multipliée par unité supplémentaire du prédicteur. Un OR supérieur à 1 augmente la probabilité de l'événement ; un OR inférieur à 1 la diminue.
Qu'est-ce qu'un rapport de cotes (odds ratio) ?
Le rapport de cotes (OR) mesure l'association entre un prédicteur et la variable dépendante. Un OR = 1 indique aucune association. Un OR = 2 signifie que la cote est deux fois plus élevée pour une unité supplémentaire du prédicteur ; un OR = 0,5 la divise par deux. L'OR est l'indice d'effet standard rapporté pour un modèle logistique.
Quelle est la différence entre régression linéaire et régression logistique ?
La régression linéaire modélise une variable dépendante continue. La régression logistique modélise la probabilité d'appartenir à l'une de deux catégories — la variable dépendante est dichotomique. Appliquée à une variable dichotomique, la régression linéaire produirait des prédictions hors de l'intervalle [0, 1], ce qui est inadmissible pour des probabilités. La transformation logit résout ce problème en modélisant le logarithme des cotes plutôt que la valeur brute.